
DB 정규화
Functional dependency (함수 종속성)
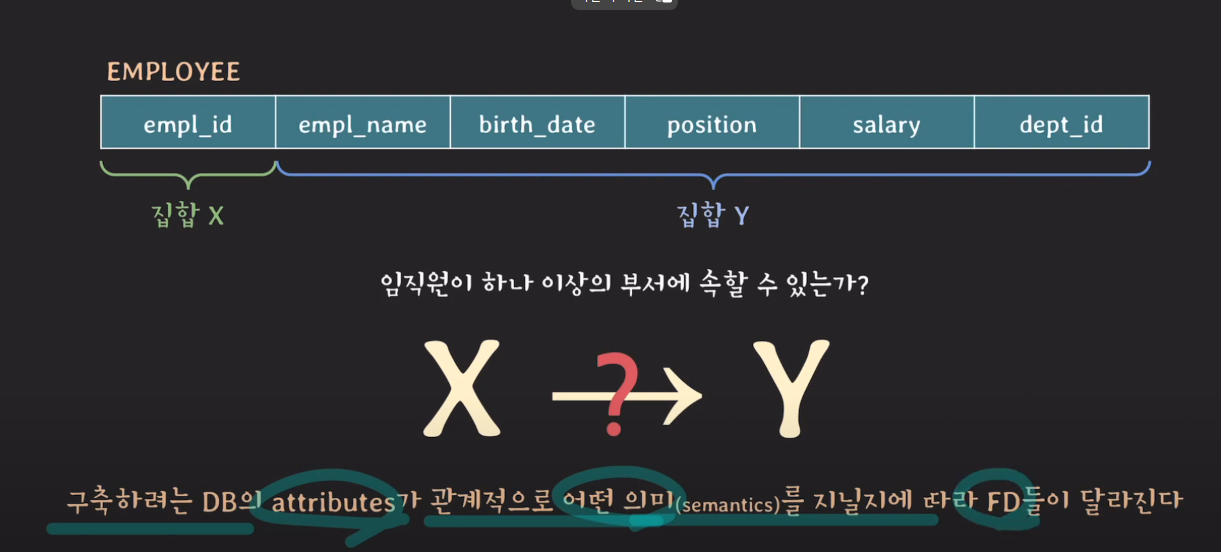
한 테이블에 있는 두 개의 attribute(s) 집합(set) 사이의 제약(a constraint)

X (left-hand side) → Y (right-hand side)
X값에 따라 Y값이 유일하게(uniquely) 결정될 때
‘X가 Y를 함수적으로 결정한다(functionally determine)’
‘Y가 X에 함수적으로 의존한다(functionally dependent)’
라고 말할 수 있고, 두 집합 사이의 이러한 제약 관계를
functional dependency(FD)라고 부른다
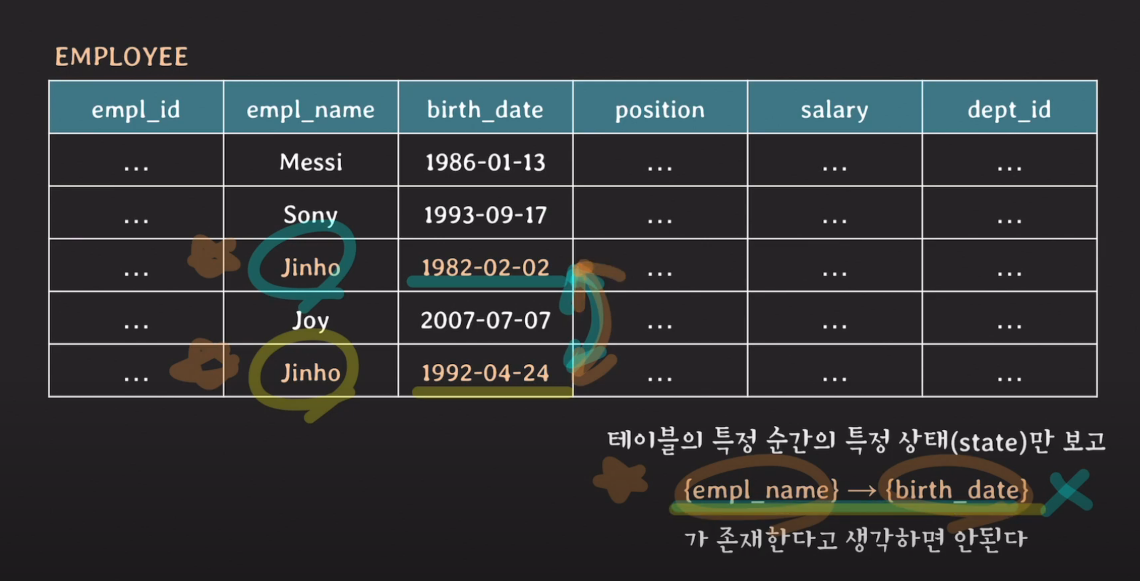
- 파악하는 방법 : 테이블의 스키마를 보고 의미적으로 파악 → 테이블의 state를 보고 파악해선 안됨
Trivial functional dependency
X -> Y이고, 이때 Y가 X의 부분집합이면 X -> Y를 trivial FD라고 한다.
ex. {a, b, c} -> {c}, {a, b, c} -> {a, b, c}
Non-trivial functional dependency
X -> Y이고, 이때 Y가 X의 부분집합이 아니면 X -> Y는 non-trivial FD라 한다.
ex. {a, b, c} -> {b, c, d}
{a, b, c} -> {d, e} <- 이 경우는 X와 Y에 겹치는 부분이 하나도 없음. 이럴땐 completely non-trivial FD라고 함
Partial functional dependency
X -> Y이고, X의 proper subset이 Y를 결정지을 수 있다면, X -> Y는 partial FD이다.
X의 proper subset : X의 부분 집합이지만 X와 동일하진 않은 집합
ex. X = {a, b} 이면 X의 proper subset은 {}, {a}, {b}가 될 수 있다.
하지만 {a, b}는 proper subset이 아니다!
partial FD의 예를 알아보자.
{empl_id, empl_name} -> {birth_date}이란 FD가 있을 때
사실 empl_id만으로 birth_date가 결정된다.
따라서 {empl_id, empl_name} -> {birth_date}는 partial FD라 할 수 있다.
Full functional dependency
X -> Y이고, X의 proper subset이 Y를 결정지을 수 없다면(즉, X 전체만이 Y를 결정지을 수 있음), X -> Y는 full FD이다.
{stu_id, class_id} -> {grade}인 FD가 있다.
하지만 {stu_id, class_id}의 proper subset인 {stu_id}, {class_id}, {}는 {grade}를 결정지을 수 없다.
따라서 {stu_id, class_id} -> {grade}는 full FD이다.
지금까지 설명한 Functional Dependency를 활용하여 DB 정규화를 할 수 있다.
DB 정규화 (normalization)
데이터 중복과 insertion, update, deletion anomaly를 최소화하기 위해 일련의 normal forms(NF)에 따라 relational DB를 구성하는 과정
Normal forms(NF)
정규화 되기 위해 준수해야 하는 몇 가지 rule
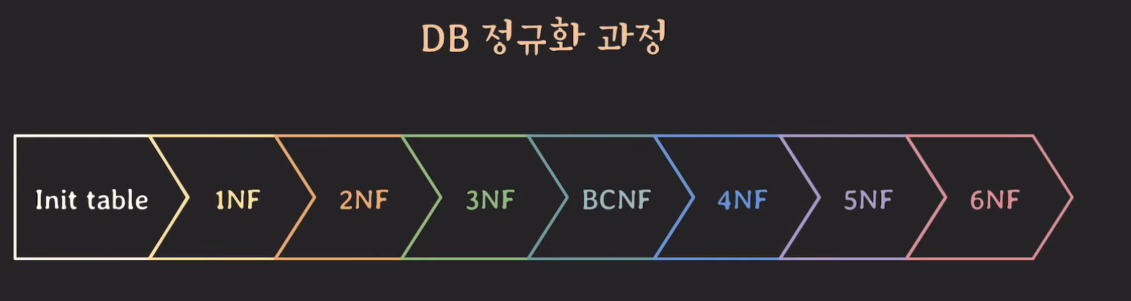
- 처음부터 순차적으로 진행하며 normal form을 만족하지 못하면 만족하도록 테이블 구조를 조정한다.
- 앞 단계를 만족해야 다음 단계로 진행할 수 있다.
- 1NF ~ BCNF는 FD와 key만으로 정의되는 NF
- 3NF까지 도달하면 정규화 됐다고 말하기도 함
- 보통 실무에서는 3NF 혹은 BCNF까지 진행 (많이 해도 4NF 정도까지만 진행)
DB 정규화 예제
| bank_name | account_num | account_id | class | ratio | empl_id | empl_name | card_id | | — | — | — | — | — | — | — | — | | | | | | | | | |
- 임직원의 월급 계좌를 관리하는 테이블
- 월급 계좌는 국민은행이나 우리은행 중 하나
- 한 임직원이 하나 이상의 월급 계좌를 등록하고 월급 비율(ratio)를 조정할 수 있다
- 계좌마다 등급(class)이 있다 (국민 : STAR → PRESTIGE → LOYAL, 우리 : BRONZE → SILVER → GOLD)
- 한 계좌는 하나 이상의 현금 카드와 연동될 수 있다.
super key
table에서 tuple들을 unique하게 식별할 수 있는 attribute의 집합
(candidate) key
어느 한 attribute라도 제거하면 unique하게 tuple을 식별할 수 없는 super key
위 테이블에선 {account_id}, {bank_name, account_num}가 key가 된다.
({account_id, bank_name, account_num}은 super key이지만 key는 아님!)
primary key
table에서 tuple들을 unique하게 식별하려고 선택된 (candidate) key
위 테이블에선 attribute 수가 1개인 {account_id}로 선택하자(꼭 그래야 하는건 아니지만 attribute 수가 적을 수록 관리가 쉬움).
prime attribute
임의의 key에 속하는 attribute
위 테이블에선 account_id, bank_name, account_num이 된다.
non-prime attribute
어떤 key에도 속하지 않는 attribute
즉 prime attribute를 제외한 나머지
Table의 Functional Dependency
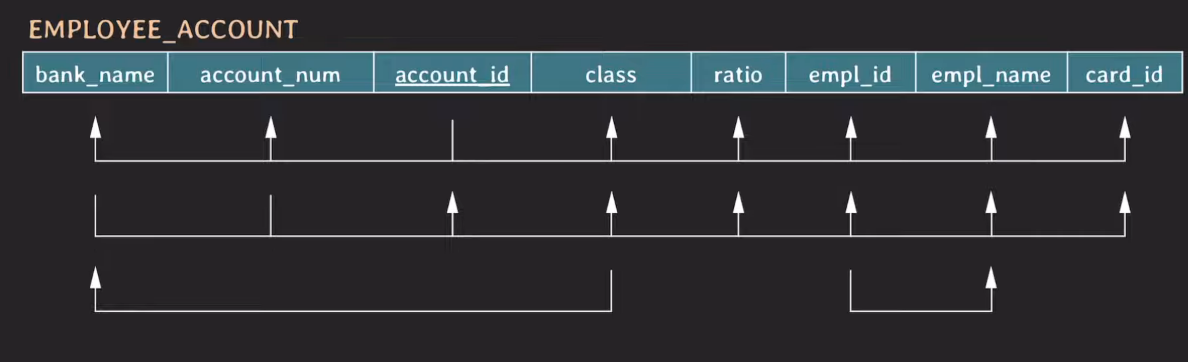
- {account_id} → {bank_name, account_num, class, ratio, empl_id, empl_name, card_id}
- {bank_name, account_num} → {account_id, class, ratio, empl_id, empl_name, card_id}
- {empl_id} → {empl_name}
- {class} → {bank_name}
1NF
attribute의 value는 반드시 나눠질 수 없는 단일한 값이어야 한다.
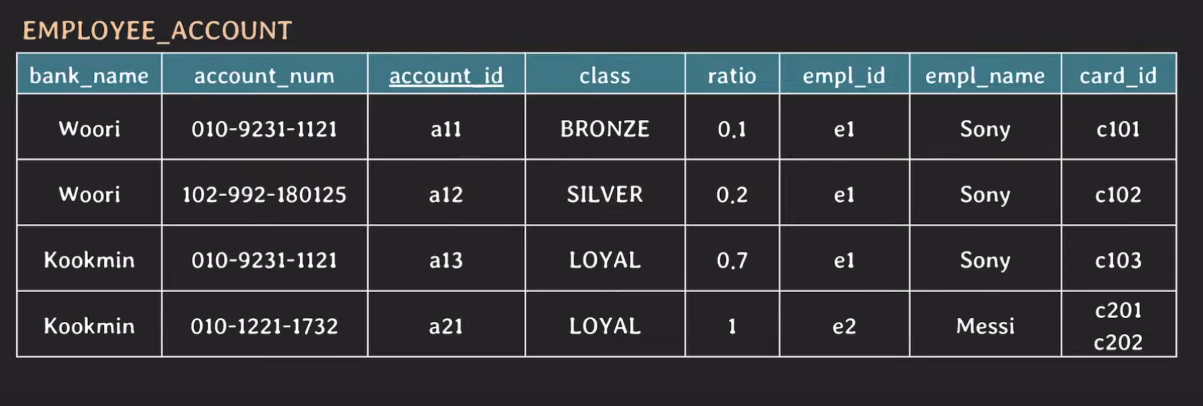
Messi의 card_id가 2개임으로 1NF를 위반하고 있음.
우선 아래처럼 row를 분리해 해결할 수 있음.
| bank_name | account_num | account_id | class | ratio | empl_id | empl_name | card_id |
|---|---|---|---|---|---|---|---|
| Woori | 010-9231-1121 | a11 | BRONZE | 0.1 | e1 | Sony | c101 |
| Woori | 102-992-180125 | a12 | SILVER | 0.2 | e1 | Sony | c102 |
| Kookmin | 010-9231-1121 | a13 | LOYAL | 0.7 | e1 | Sony | c103 |
| Kookmin | 010-1221-1732 | a21 | LOYAL | 1 | e2 | Messi | c201 |
| Kookmin | 010-1221-1732 | a21 | LOYAL | 1 | e2 | Messi | c202 |
이렇게 하면 1NF 문제는 해결되지만 중복 데이터가 생기고 primary key도 변경을 해야 한다(primary key인 account_id가 중복되어 더 이상 다른 attribute을 식별하지 못하게 됨).
또한 ratio 부분도 이상하게 된다.
우선 primary key는 card_id를 추가함으로써 해결할 수 있다.
(candidate) key는 {account_id, card_id}, {bank_name, account_num, card_id}로 바뀌게 된다.
non-prime attribute는 class, ratio, empl_id, empl_name가 된다.
{account_id, card_id}
근데 가만히 살펴보면 non-prime attribute는 account_id, card_id 두 개 모두에 의존적일 필요가 없다. account_id에만 의존적이여도 되는 값들이다.
즉 모든 non-prime attribute들이 {account_id, card_id}에 partially dependent 하다.
이는 {bank_name, account_num, card_id}인 경우도 똑같다. 설명은 생략한다.
2NF
모든 non-prime attribute는 모든 key에 fully functionally dependent 해야 한다. → 엔터티의 일반속성은 주식별자 전체에 종속적이어야 한다.
우리의 테이블에선 card_id라는 attribute 때문에 이런 문제가 발생했다. 따라서 테이블을 분리해서 해결해 보겠다.
문제가 되는 card_id를 분리하자.
ACCOUNT_CARD
| account_id | card_id |
|---|---|
| a11 | c101 |
| a12 | c102 |
| a13 | c103 |
| a21 | c201 |
| a21 | c202 |
이렇게 card_id를 분리해내면 원래 테이블을 다음과 같이 줄일 수 있다.
EMPLOYEE_ACCOUNT
| bank_name | account_num | account_id | class | ratio | empl_id | empl_name |
|---|---|---|---|---|---|---|
| Woori | 010-9231-1121 | a11 | BRONZE | 0.1 | e1 | Sony |
| Woori | 102-992-180125 | a12 | SILVER | 0.2 | e1 | Sony |
| Kookmin | 010-9231-1121 | a13 | LOYAL | 0.7 | e1 | Sony |
| Kookmin | 010-1221-1732 | a21 | LOYAL | 1 | e2 | Messi |
그리고 이제 EMPLOYEE_ACCOUNT 테이블이 2NF를 만족함을 알 수 있다.
{account_id} -> {bank_name, account_num, class, ratio, empl_id, empl_name}
{bank_name, account_num} -> {account_id, class, ratio, empl_id, empl_name}
모두 fully FD가 된다.
ACCOUNT_CARD 역시
{card_id} -> {account_id}가 fully FD 임으로 2NF를 만족한다!
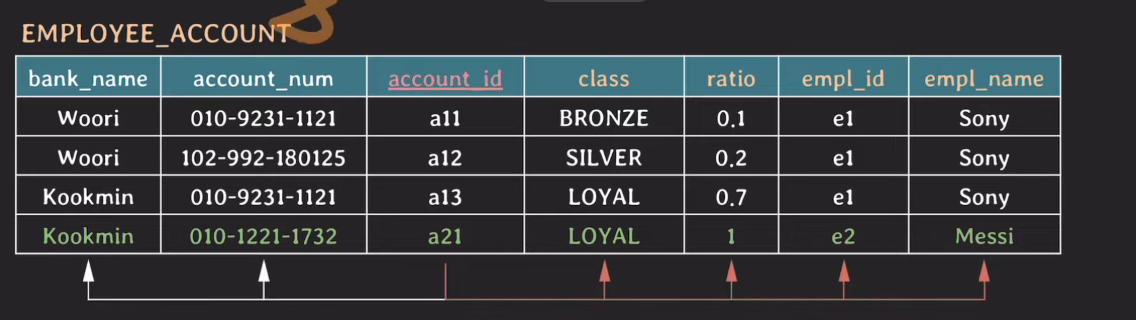
3NF
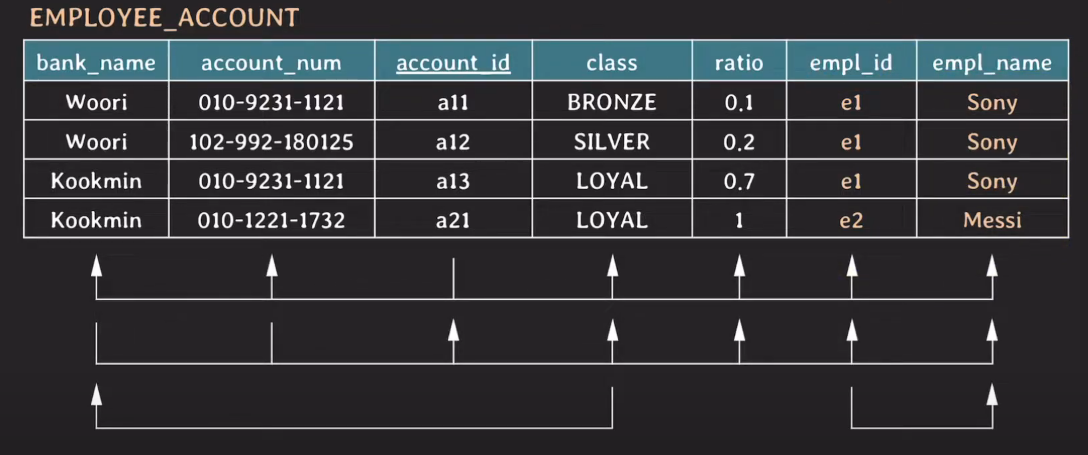

- {account_id} → {bank_name}은 2번째 문장을 성립하지 않음
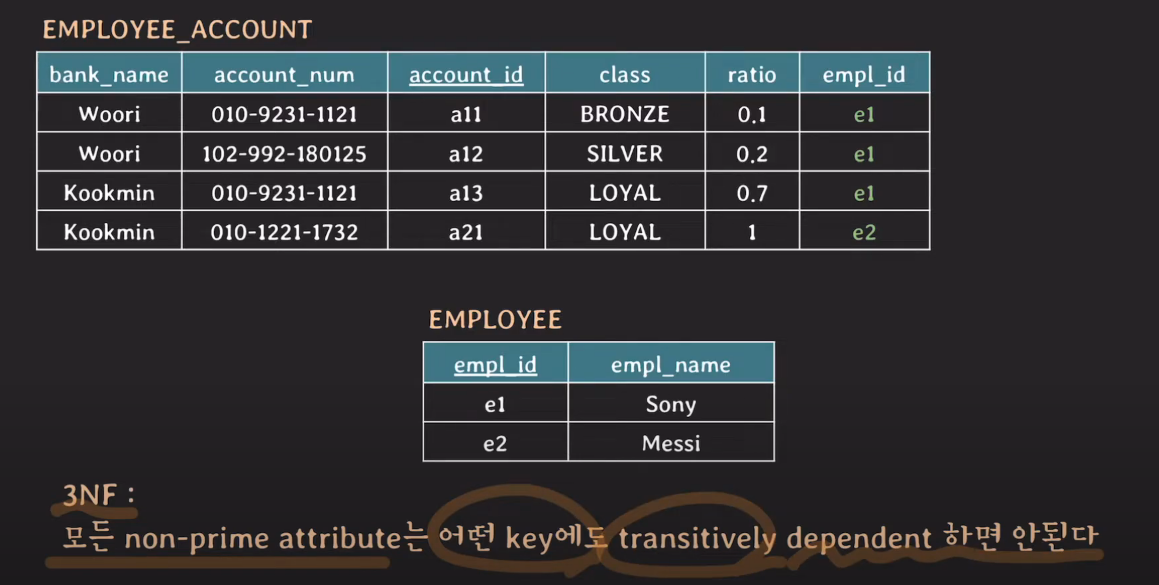
- 3NF까지 되면 정규화됐다 라고 말할 수 있다.
참조
DB에서 functional dependency(FD: 함수 종속)
Leave a comment